For ML Illiterates: How LLMs Generate Output
Introduction
One friend asked why LLMs generate different outputs every time. Especially sometimes they generate wrong answers on questions requiring certain knowledge. They sometimes know the truth and sometimes they do not. How?
This question originates from lack of understanding on how LLMs generate output. I will try to explain with a simple example.
LLM Training
LLMs are trained to predict next token given a sentence which is called a prompt. It is crucial to understand that LLM output is token. Not a paragraph, not a sentence, even not a word. A token can be a word or a part of a word. For the sake of simplicity lets assume our tokens are equivalent to words.
During training an LLM model reads a lot of text from wide range of sources and topics. At the end of training it learns how the language works. This learning may not be like you imagine. It learns relationship between words (tokens). It learns how likely is a word to follow a given text.
One of the benefits of next word prediction is that it enables a model to acquire knowledge about the syntax and semantics of the language, as well as factual information about the world.
Another crucial thing to understand is that next word prediction is not about outputting next word directly. Instead the model generates a distribution on possible next words. The most likely word will have a high probability but irrelevant words will also have non-zero probabilities.
LLM Inferencing
Once training is complete, an LLM can be used for generating text output,called as inferencing.
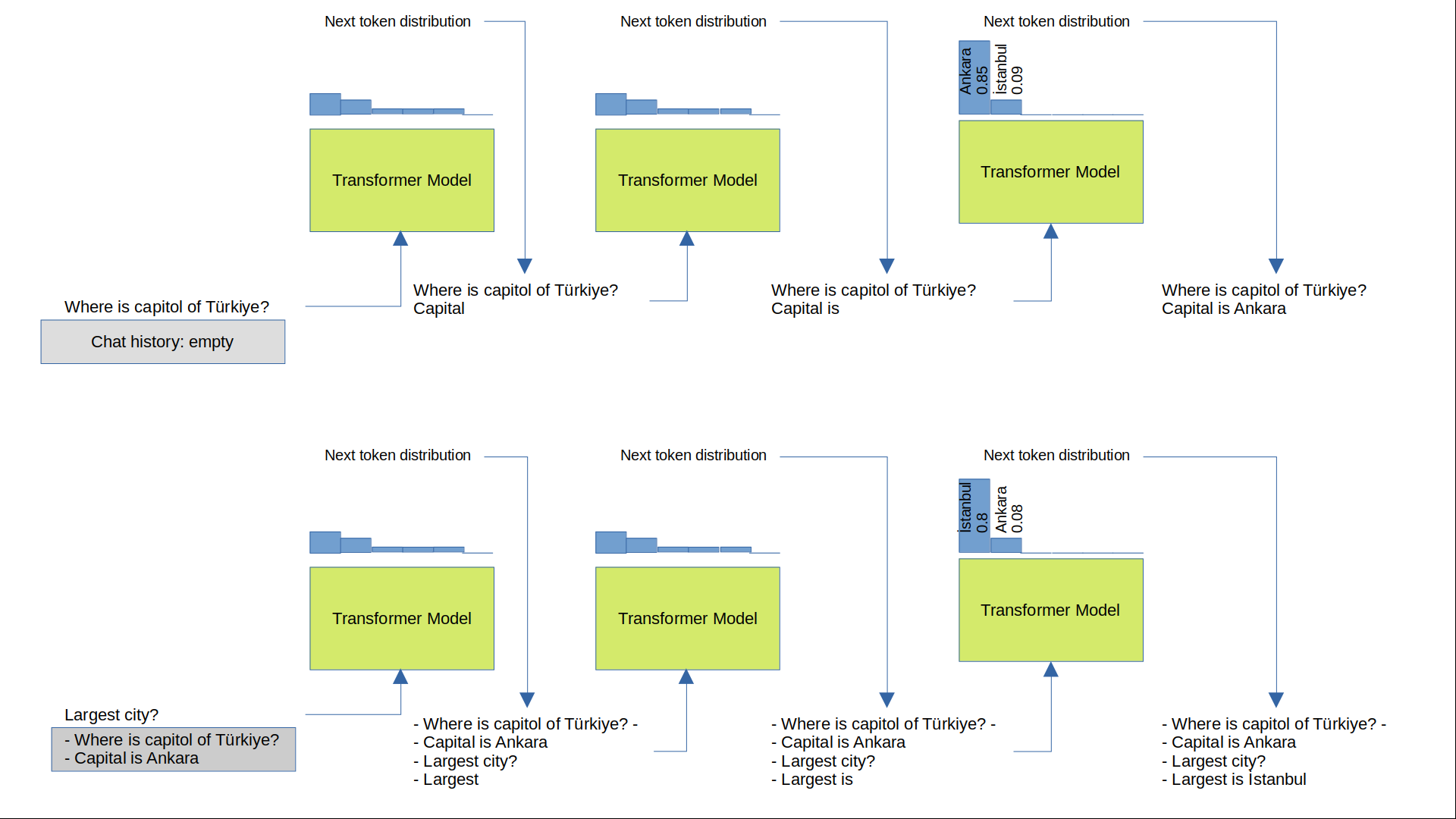
Remember that our model can only predict the next word given the input. To obtain a complete answer, we need to append the predicted word to the input and feed it back to the model at each generation step. This iterative process of generating words one by one is called decoding.
Please see Figure 1 for illustration of the decoding process.
Sampling
For the same input, a model, in general, will generate the same output. This is not desirable for text generation tasks that require creativity. Let’s assume you need a cooking recipe. A model generating the same recipe all the time would not be useful.
Some tasks need precise output, like question answering. For example, capital of Turkey do not change from time to time.
A language model supports both output style via sampling. One sampling method widely used is temperature based sampling. Temperature is a number between 0 and 1. When temperature is 0, most likely tokens will be selected at each step. As temperature approaches to 1, model becomes more likely to generate output based on less likely tokens.
Consider the next token distribution about capital in Figure 1. Ankara has a probability of 0.85 which is very high. However, if temperature is close to 1, less likely tokens like İstanbul, Bursa or İzmir can be selected. Depending on how close temperature is to 1, even completely irrelevant tokens can be selected, like flower, car, iskender etc. This is because the model output distribution is over full vocabulary.
Final Notes
- Note that capitol is not the right word but the model still produces the correct answer. Because word capitol is placed closed to word capital in vector space.
- Note that word Türkiye is used but not english word Turkey. The answer is still correct because Türkiye and Turkey are closely placed in the vector space of the model.
- Note that second question does not refer to Turkey but model understands that the question is about Turkey. Because model input is the prompt plus the conversation history.
- Note that, at the final stage, just before the final token is generated, all history, prompt, and generated tokens are fed into the model to generate the last token. Let’s call all the text fed into the model a context. LLMs come with a context size limit. Context cannot exceed this limit. For example, most known chat models ChatGpt and Gpt-4 have 4096 and 8K token limits respectively.