ZEPHYR: DIRECT DISTILLATION OF LM ALIGNMENT Paper Notes
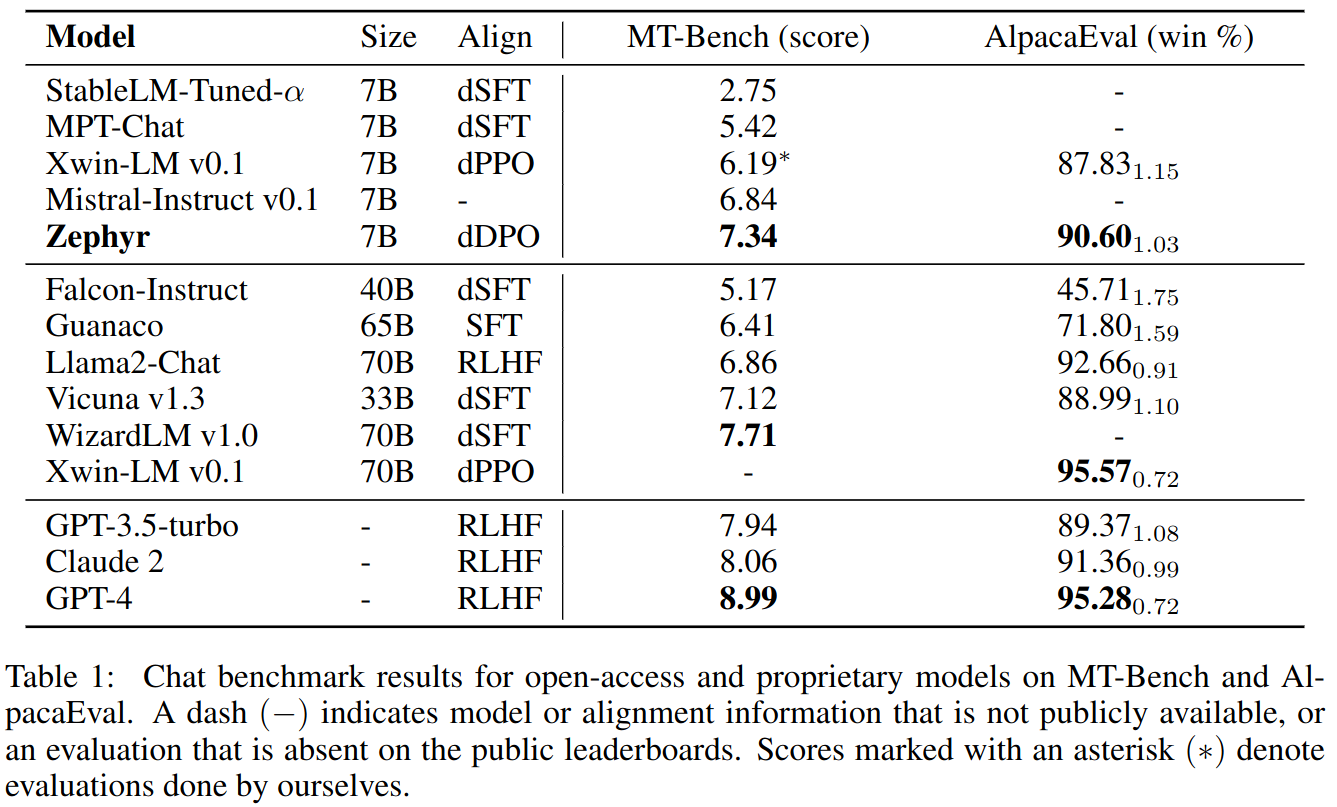
Using dSFT (Distilled Supervised Finetunning) improves model accuracy. However, dSFT models lack alignment. The paper demonstrates that the application of dDPO (Distilled Direct Policy Optimization), where a teacher model is used to rank outputs, leads to a model that is significantly improved intent alignment. In particular, results on MT-Bench show that ZEPHYR-7B surpasses LLAMA2-CHAT-70B, the best open-access RLHF-based model

Introduction
In dSFT output of a more capable teacher is used as supervised training data for a student model. dSFT improves student model performance but not to the level of the teacher model.
dSFT models lack intent alignment which ofted leads to incorrect responses.
Evaluation benchmarks MT-Bench and AlpacaEval targets intention alignment.Evaluation benchmarks show that proprietary models perform better than open models trained with human preferences which in turn performs better than distilled models.
dSFT is used to fine-tune Mistral-7B on UltraChat dataset. dDPO is used to align dSFT Model on UltraFeedback dataset.
This work is concerned with intent not alignment and does not consider safety aspects.
Method
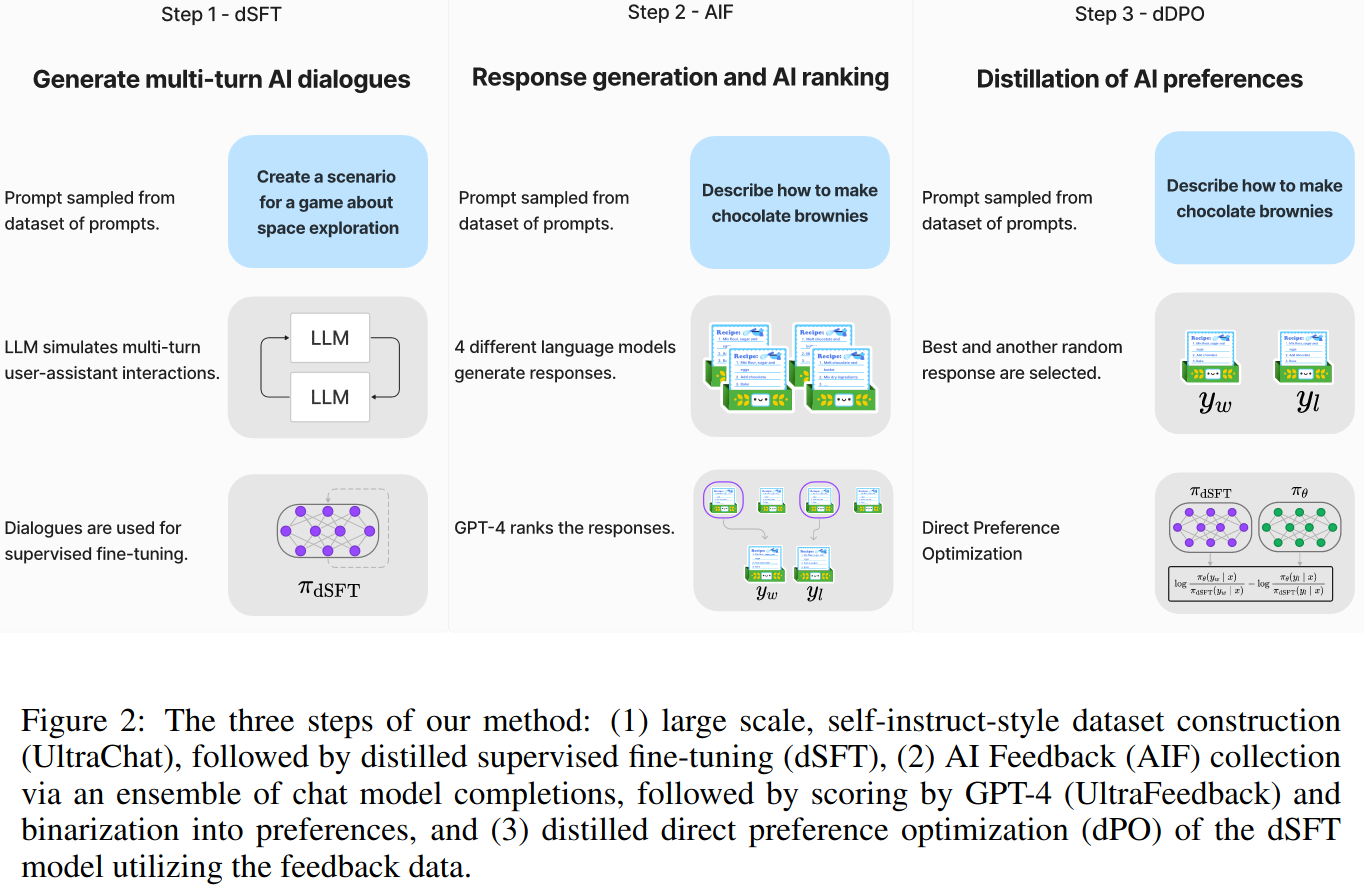
Distilled Supervised Fine-Tuning (dSFT)
A base LLM is fine-tuned to respond user prompts using a supervised fine tunning dataset. In distilled supervised fine tunning, dataset is generated by a model.
Self-instruct method is used to generate the dataset. Let x1, x2, …, xj be a set of seed prompts which represent a diverse set of topics. The dataset is constructed through iterative self-prompting where the teacher model is used to both respond to an instruction and refine the instruction based on the response. For each x, response y is sampled from the teacher. Then refine by sampling new instruction x’ (using a refinement prompt). Final dataset is C={(x1,y1), …, (xj,yj)}.
AI Feedback through Preferences (AIF)
TO collect AI feedback, approach of UltraFeedback is used. The method starts with a set of prompts x1, …, xj. Each prompt x is fed to a collection of four models e.g. Claude, Falcon, Llama etc. and responses y1,…,y4 are yielded. The responses are fed to the teached to obtain a score. Highest scoring response is selected as the winning response, yw. A random lower scoring response is selected as the loosing response, yl. The final dataset is D={(x1,yw1,yl1), …, (xj, ywj, ylj)}.
Distilled Direct Preference Optimization (dDPO)

EXPERIMENTAL DETAILS
- Base model is Mistral 7B
- TRL, DeepSpeed ZeRO-3, FlashAttention-2
- AdamW optimizer and no weight decay
- 16 A100s using bfloat16 precision and typically took 2-4 hours to complete
Datasets
A subset of UltraChat dataset which corresponds to 200K samples is used in SFT stage. UltraFeedback dataset is used in alignment stage.
Evaluation
MT-Bench: Multi-turn benchmark. Model response is rated by GPT-4 on a scale from 1-10. AlpacaEval: Single-turn benchmark. Model response is compared to a baseline model response e.g. text-davinci-003 by GPT-4 to generate a win-rate score.
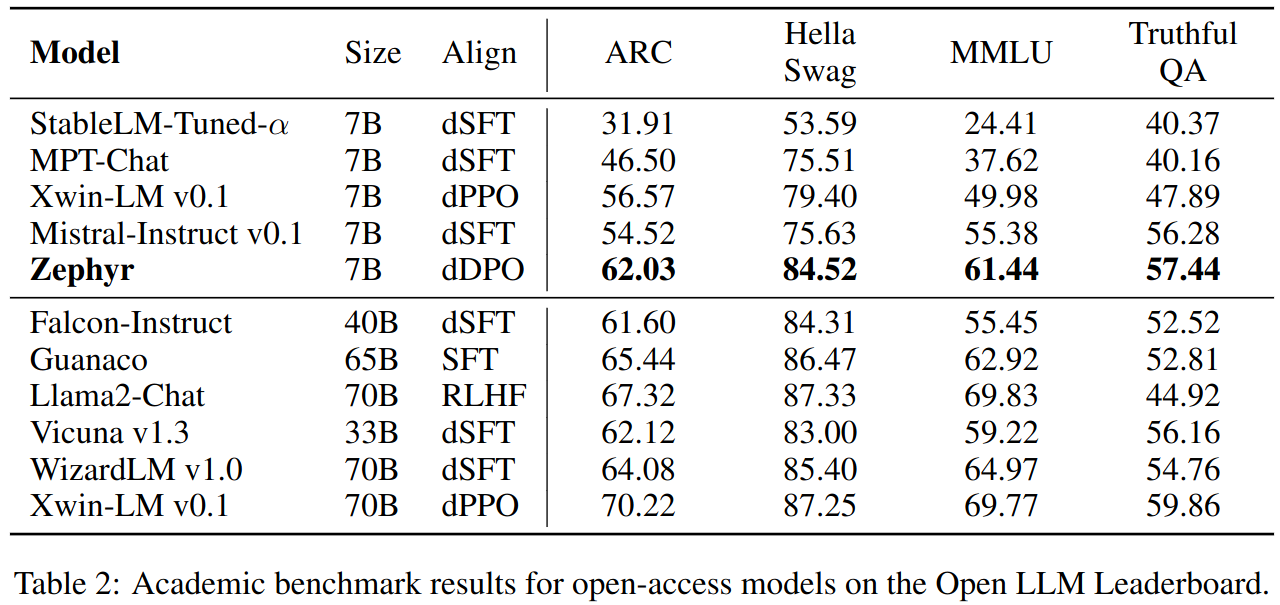
Additionally ARC, HellaSwag, MMLU and TruthfulSQ benchmarks are used to determine whether fine-tunning caused any regression on the based model’s reasoning and truthfulness capabilities.
SFT Training Details
- 1-3 epochs
- Cosine learning rate scheduler with a peak learning rate of 2e-5 and 10% warmup steps.
- Global batch size is 512
- Sequence length is 2048
DPO Training Details
- 1-3 epochs
- Linear learning rate scheduler with a peak learning rate of 5e-7 and 10% warmup steps.
- Global batch size is 32, β is 0.1.
- Final Zephyr model was initialized from SFT model that was trained for 1 epoch and alined with 3 DPO epochs.

Results and Ablations
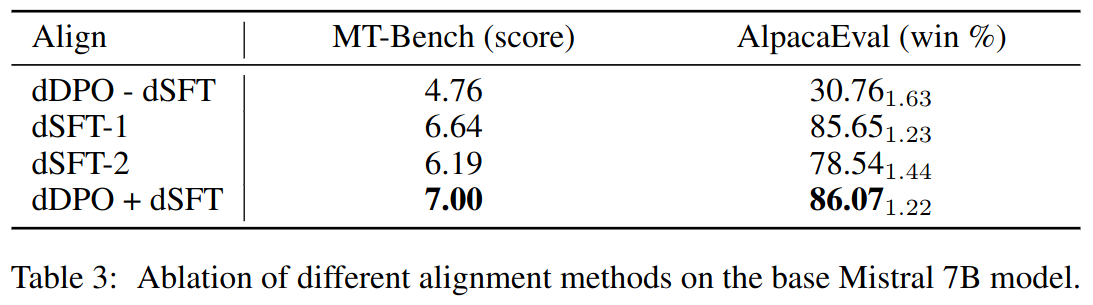
In table 3:
- dDPO - dSFT fine-tunes the base model directly with DPO for one epoch on UltraFeedback.
- dSFT-1 fine-tunes the base model with SFT for one epoch on UltraChat.
- dSFT-2 applies dSFT-1 first, followed by one more epoch of SFT on the top-ranked completions of UltraFeedback.
- dDPO + dSFT applies dSFT-1 first, followed by one epoch of DPO on UltraFeedback.
Does Overfitting Harm Downstream Performance?
Authors found that after one epoch of DPO trainin the model overfits. However this does not harm model performance. Actually best model is obtained with one epoch of SFT and followed by three epochs of DPO training. On the contrary, SFT training for more that one epochs harms DPO performance.
Disclaimer: GPT-4 which is used as judge in MT-Bench and AlpacaEval benchmarks is known to be biased towards models distilled from it or those produce verbose but potentially incorrect responses.