QLoRA: Efficient Finetuning of Quantized LLMs
Contributions:
4-bit NormalFloat (NF4): An information theoretically optimal quantization data type for normally distributed data that yields better empirical results than 4-bit Integers and 4-bit Floats.
Double Quantization A method that quantizes the quantization constants, saving an average of about 0.37 bits per parameter (approximately 3 GB for a 65B model).
Paged Optimizers using NVIDIA unified memory to avoid the gradient checkpointing memory spikes that occur when processing a mini-batch with a long sequence length.
With Qlora it becomes possible to fine-tune a 65B model which required 780GB of GPU memory with a single 48GB GPU.
A pretrained model is quantized to 4-bit. Then a set of learnable low-rank adapters weights are added. Adapters are tuned by backpropagation.
Introduction
Finetunning Observations:
Data quality is far more important than dataset size, (For exmaple: a 9k sample dataset (OASST1) outperformed a 450k sample dataset (FLAN v2, subsampled) on chatbot performance, even when both are meant to support instruction following generalization.)
Dataset suitability matters more than size for a given task. (For example: strong Massive Multitask Language Understanding (MMLU) benchmark performance does not imply strong Vicuna chatbot benchmark performance and vice versa)
Background
Block-wise k-bit Quantization
Quantization is process of discretizing an input from a representation that holds more information to a represenation that holds less information. e.g. 32-bit floats to 8-bit ingegers.
Assume input elements are in the form of tensors. To ensure entire range of low bit data type is used, thwe input data type is rescaled into target data type range through normalization by the absolute maximum of the input elements.
Following figure shows how an 32-bit floating point tensor is quantized into 8-bit tensor with range [-127, 127].
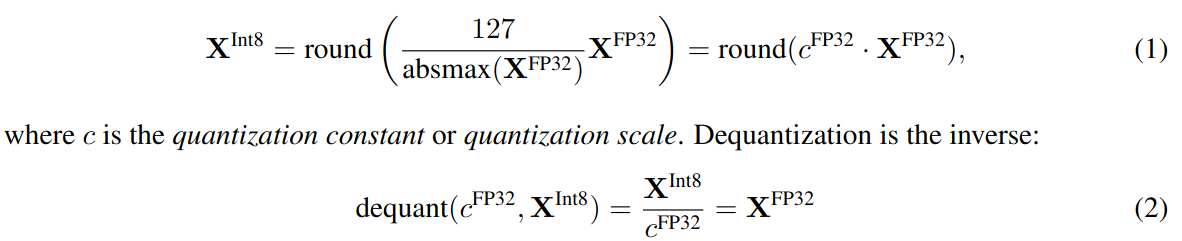
The problem is that if a large magnitude value occurs in the input tensor, then quantization bins are not utilized well. e.g. few or none numbers are quantized into some bins.
To prevent outlier issue, a comman approach is to chunk input tensor into block that are independently quantized, with a seperate quantization constant c. For n different blocks we will have n different quantization constants.
Low-rank Adapters
Model parameters are fixed. Adapter parameters are updated during gradient descent.
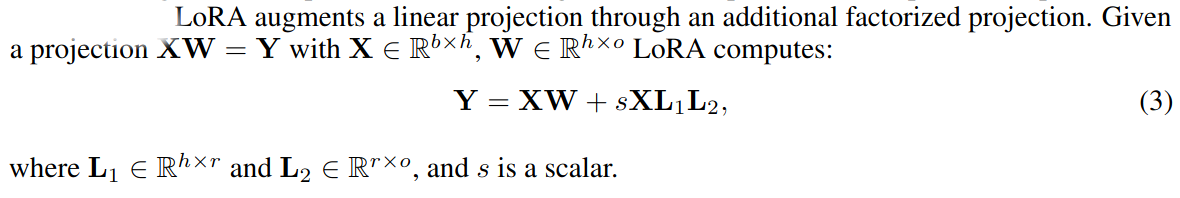
Memory Requirement of Parameter-Efficient Finetuning
Activation gradients uses significant amount of memory. This is more obvious in Lora.
For example, a 7B model trained on FLAN v2 with a batch size of 1, lora input gradients have a memory footprint of 567MB while lora parameters take up only 26MB. (In typical scenario where LoRA weights equivalent to commonly used 0.2% of the original model weights ).
With gradient checkpointing, the input gradients reduce to 18MB. In contrast, quantized base model takes up 5048 MB of memory.
To conclude, amount of lora parameters should not be tuned for porpuse of saving memory as lora parameters are inportant for performance of the final model.
QLoRA Finetuning
QLoRA has one low-precision storage type: 4-bit. It has one computation data type: BFloat16. Whenever a QLoRA weight tensor is used, it is dequantized to BFloat16 first.
4-bit NormalFloat Quantization: The NormalFloat (NF) data type builds on Quantile Quantization which ensures enach quantization bin has an equal number of values assigned from the input tensor. However, quantile estimation is expensive. Fast estimation algorithms comes with large quantization errors for outliers, which are very important.
Pretrained neural network weights usually have a zero-centered normal distribution with standard deviation \(\sigma\). It is possible to transform all weights to a single fixed distribution by scaling \(\sigma\). Having all input tensors sharing the same quantiles, it is no longer necessary to make expensive quantile estimates. Our data type is in [-1, 1] range. After scaling weights are in [-1,1] range. Also note that scaling constants, absolute maximum values, needs to be stored as well.
Following image, taken from a lecture from (see reference 4) by Tim Dettmers, illustrates how nf4 data type is created.

Double Quantization: Scaling constants, absolute maximum values, takes up significant memory. They can be quantized as well for more memory savings.
In QLoRA, optimal block size is 64 (see reference 4 for more info.). If quantization (scaling) constants are 32 bit, then each constant adds \(32/64=0.5\) bits per parameter.
In second quantization, 8 bit floats are used together with block size 256. Then memeory consumption for a quantization constant becomes, \(8/64 + 32/(64*256) = 0.127\) bits per parameter. This may not look much but as model size gets largers, it makes a huge difference on whether the GPU memory is sufficient.
Paged Optimizers: Nvidia Unified memory feature is utilized to have a paging logic. Optimizer states are pushed to CPU RAM when more GPU Memory is needed. They are pulled back to GPU Memory when needed.
QLoRA: QLoRA has two data types: NF4 for storing network weights and BF16 for computation. Stora data type is dequentized into computation data type to computing forward and backward passes. Gradients are only calculated for the Lora parameters.

QLoRA vs. Standard Finetunning
Hyper parameters for QLoRA:
- The most critical LoRA hyper-parameter is how many LoRA adapters are used intotal.
- LoRA should be used on all layers to match full finetunning performance.
- LoRA dropout 0.05 is useful for small models (7B, 13B), but not for larger models (33B, 65B).
- LoRA projection dimension r is unrelated to final performance if LoRA is used on all layers
- LoRA α is always proportional to the learning rate.
Figure 2 of the paper shows that using LORA on all transformer layers is needed to match 16-bit full finetunning performance.
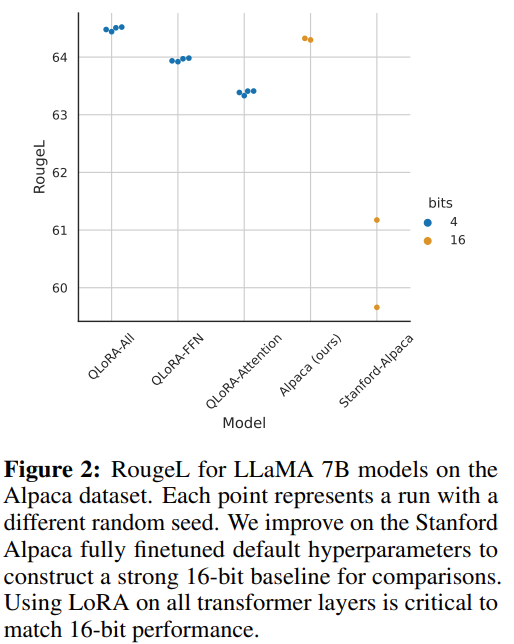
Figure 3 of the paper shows that nf4 improves performance over fp4. Double quantization does not degrade performance.
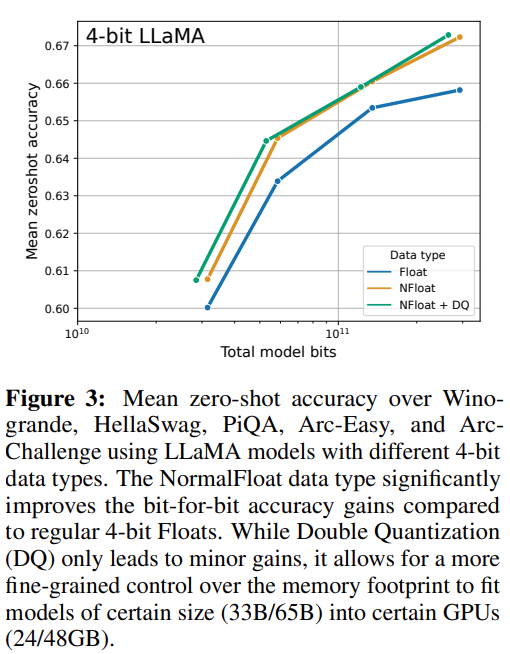
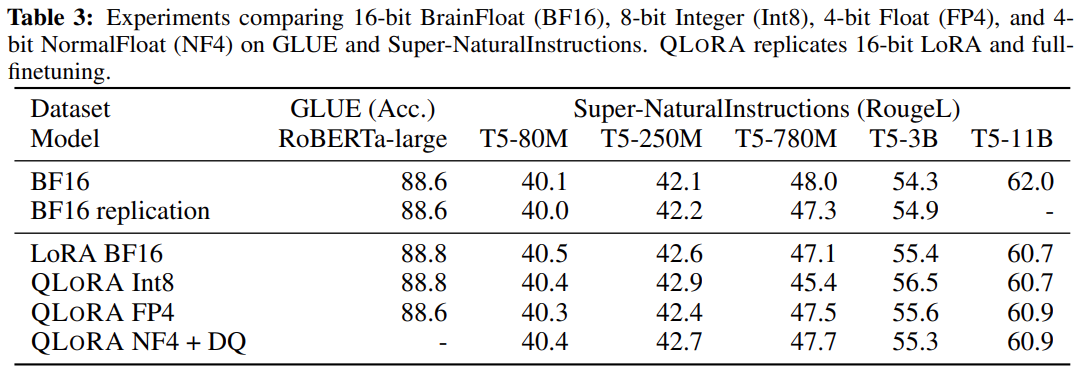
Table 3 of the paper shows that performance lost due to quantization errors can be recovered by adapeter finetunning after quantization. Trained adapters learns to compansate for quantization errors.
Pushing the Chatbot State-of-the-art with QLoRA
Hyper-parameters:
- LoRA r = 64, α = 16.
- LoRA modules for all linear layers of the base model.
- Adam beta2=0.999
- max grad norm = 0.3
- LoRA dropout 0.1 for models upto 13B and 0.05 for larger models (33B and 65B).
- Constant learning schedule
- Group-by-length (this produces oscillating loss curve)
Ablation:
Table 10 of the paper shows that training on only response is better than training on complete instruction.

Final Notes:
- Overall results show that 4-bit QLORA is effective and can produce state-of-the-art chatbots.
- Automated evaluation systems e.g. gpt have noticeable biases. Dataset
- Quality rather than dataset size is critical for mean MMLU accuracy.
References
- Qlora paper
- Qlora code repository
- Bits and Bytes code repository
-
[Democratizing Foundation Models via k-bit Quantization - Tim Dettmers Stanford MLSys #82](https://www.youtube.com/watch?v=EsMcVkTXZrk)