Microsoft Research - Phi Family Notes
TinyStories: How Small Can Language Models Be and Still Speak Coherent English? (April 2023)
- The paper explores whether tiny models can generate coherent English text.
- Generates a synthetic dataset,TinyStories, of short stories that only contain words that a typical 3 to 4-year-olds usually understand, generated by GPT-3.5 and GPT-4.
- The paper shows that TinyStories dataset can be used to train and evaluate LMs that are much smaller than the state-of-the-art models (below 10 million total parameters with an embedding dimension of 256), or have much simpler architectures (with only one transformer block), yet still produce fluent and consistent stories with several paragraphs that are diverse and have almost perfect grammar, and demonstrate reasoning capabilities.
- Introduces a new paradigm for evaluating language models using GPT-4, which overcomes many of the limitations of standard benchmarks.
- Training of generative models on TinyStories can typically be done in less than a day on a single GPU, they still exhibit many behaviors similar to the ones observed in LLMs, such as scaling laws,trade-offs between width and depth, etc. Even with limited computational resources, it is possible to conduct extensive experiments to study the effects of different hyper-parameters, architectures and training methods on the performance and quality of the models.
- Small LMs appear to be substantially more interpretable than larger ones. When models have a small number of neurons and/or a small number of layers, both attention heads and MLP neurons have a meaningful function: Attention heads produce very clear attention patterns, with a clear separation between local and semantic heads, and MLP neurons typically activated on tokens that have a clear common role in the sentence.
- In order to achieve diversity in the generated stories, a vocabulary of 1500 basic words, typical words a 3-4 years old use, separated into nouns, verbs, and adjectives is collected. In each generation, 3 words are chosen randomly (one verb, one noun, and one adjective). The model is instructed to generate a story that somehow combines these random words into the story.
- In addition, a list of possible features a story could have (such as a dialogue, a plot twist, a bad ending or a moral value) is constructed. For each story we generated a random subset of those features and prompted the model with the extra requirement for the story to have these features.
Example prompt: Write a short story (3-5 paragraphs) which only uses very simple words that a 3 year old child would likely understand. The story should use the verb ”decorate”, the noun ”thunder” and the adjective ”ancient”. The story should have the following features: the story should contain at least one dialogue, the story has a bad ending. Remember to only use simple words!
Additional Findings:
- Width is more important for capturing factual knowledge whereas depth is more important for contextual tracking – Shallower models perform better in terms of grammar compared to content consistency, meaning that model depth is more important for keeping consistent with the content than for generating syntactically correct language – Score for grammar plateaus at an earlier stage than the other two scores. – while grammar can be mastered by relatively small models, consistency and creativity only emerge at a larger size. – TinyStories (with roughly 80M parameters) reaches almost perfect scores in terms of grammar and consistency. However, it falls short of GPT-4’s abilities in terms of creativity quite significantly, suggesting that creativity continues to improve more substantially with the sizes of the model and dataset, compared to grammar and consistency. – Ability to generate a completion that is consistent with the beginning of the story emerges when the hidden size of the model increases from 64 to 128. – Models that have only 1 layer seem to struggle quite substantially with following instructions (which likely heavily relies on global attention) – 2 layers seem to be sufficient for a certain extent of instruction-following. – The quality of instruction-following depends more heavily on the number of layers, in comparison with the coherence of the plot for which the hidden dimension is more important. – The results show that as the embedding dimension and the number of layers increase, the performance in regards to all three categories improve. The models with higher embedding dimensions and more layers tend to generate more accurate, relevant, and natural continuations, while the models with lower embedding dimensions and fewer layers tend to generate more nonsensical, contradictory, or irrelevant continuations – One interesting finding is that knowledge of facts seems to rely more on the embedding dimension, whereas for context-tracking the number of layers is more important. The embedding dimension is more crucial for capturing the meaning and the relations of words, while the number of layers is more crucial for capturing long-range dependencies in the generation.
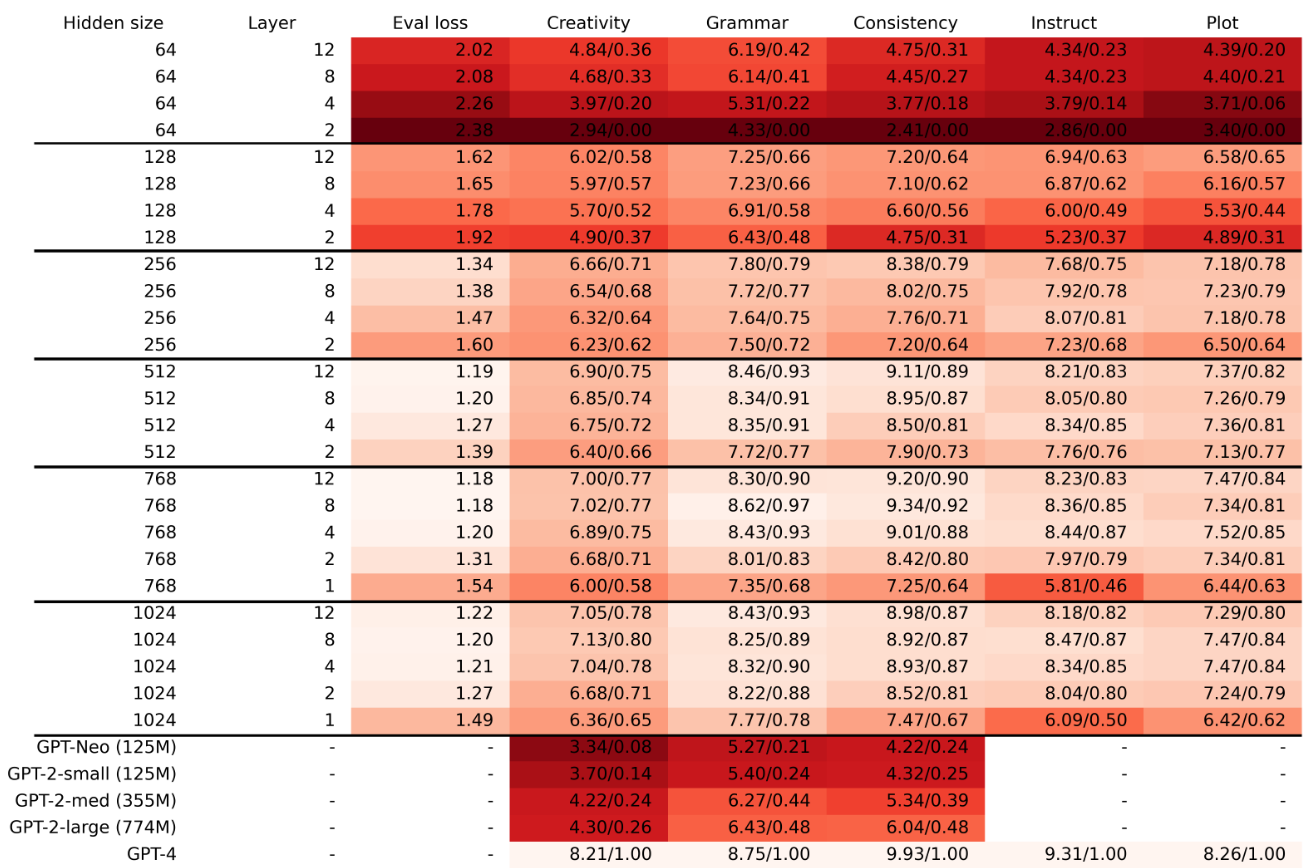
- Models with a small number of layers have a hard time staying in context, even if they do manage to produce syntactically correct English. This suggests that the model lacks the ability to capture the long-term dependencies and the structure of the story. On the other hand, models with more layers can better maintain the consistency and the logic of the story.
- In terms of emergence, grammatical and syntactic abilities appear earlier than the ability to produce consistent text, which in turn appears ahead of ability to generate content that would be considered as creative.
Interpretability
Attention Heads
Our findings suggest that the attention heads exhibit diverse and meaningful functions, such as attending to the previous word, the subject of the sentence, the end of the sentence, or the main topic of the story. We also observe that some attention heads specialize in generating certain types of words, such as nouns, verbs, or punctuation. These results suggest that the attention heads learn to perform different linguistic tasks and capture different aspects of the stories.
MLP
We use the method similar to [18] to identify the most influential tokens in the MLP for each neuron. We find that some neurons are activated on words that have a specific role in the sentence (such as the subject or the action), or in the story (such as the introduction of the protagonist). These findings suggest that the neurons in the MLP learn to encode different semantic and stylistic information and influence the generation process.
Future Direction:
Is synthesizing a refined dataset can be beneficial in training networks for practical uses?
Textbooks Are All You Need (Jun 2023)
The paper explores using small models for a more practical use case: writing simple Python functions from their doc strings. They show that improving data quality can dramatically change the shape of the scaling laws, potentially allowing to match the performance of large-scale models with much leaner training/models and reduce dataset size and training compute.
The paper introduces phi-1, a 1.3B parameters model for code, trained using a selection of “textbook quality” data from the web and synthetically generated textbooks and exercises with GPT-3.5.
- phi-1-base, trained using CodeTextbook dataset.
- phi-1, phi-1-base is fine-tuned using CodeExercises
- phi-1-small, a smaller model with 350M parameters trained with the same pipeline
Filtering of existing code datasets using a transformer-based classifier
The paper argues that web based code sources are not optimal for teaching the model how to reason and plan algorithmically because:
- Many samples are not self-contained
- Typical examples do not involve any meaningful computation, but rather consist of trivial or boilerplate code
- Samples that do contain algorithmic logic are often buried inside complex or poorly documented functions, making them difficult to follow or learn from.
- The examples are skewed towards certain topics or use cases, resulting in an unbalanced distribution of coding concepts and skills across the dataset
Language models would benefit from a training set that has the same qualities as a good “textbook”: it should be clear, self-contained, instructive, and balanced.
GPT-4 used to annotate quality of a small set of files in the web dataset. GPT-4 is prompted to determine its educational value for a student whose goal is to learn basic coding concepts. Annotated dataset is used to train a random forest based classifier that predicts the quality of a file/sample using its output embedding from a pre-trained codegen model as features.
Experiment on effect of filtering is shown using 350M parameter model:
- Unfiltered Stack (deduplicated python) and StackOverflow, the HumanEval performance saturates at 12.19% even after training for 96k steps
- Training on the filtered subset achieves 17.68% on HumanEval after 36k steps
- By training on a combination of the filtered dataset and the synthetic textbooks dataset, improved this to 20.12%.
Creation of synthetic textbook-quality datasets
Main challenges in creating a high-quality dataset for code generation is ensuring that the examples are diverse and non-repetitive. Diversity means examples should cover a wide-range of coding concepts, skills, and scenarios, and that they should vary in their level of difficulty, complexity, and style. Diversity is important for several reasons:
- It exposes the language model to different ways of expressing and solving problems in code,
- it reduces the risk of over-fitting or memorizing specific patterns or solutions
- it increases the generalization and robustness of the model to unseen or novel tasks.
For the synthetic textbook dataset diversity is achieved by providing constraints on topics and target audience of the generated textbook. For the CodeExercises dataset, diversity is achieved by constraining the function names.
Architecture
- FlashAttention implementation of multi-head attention
- MHA and MLP layers in parallel configuration
- 1.3B model: 24 layers, hidden dimension 2048, MLP-inner dimension of 8192, 32 attention heads of dimension 64 each.
- 350M model: 20 layers, hidden dimension 1024, MLP-inner dimension of 4096, 16 attention heads of dimension 64 each.
- Rotary position embeddings with rotary dimension 32.
Training data
- CodeTextbook dataset contains two sources (total of 7B tokens):
- A filtered code-language dataset, which is a subset of The Stack and StackOverflow, obtained by using a language model-based classifier. (6B tokens)
- A synthetic textbook dataset consisting of <1B tokens of GPT-3.5 generated Python textbooks.
- CodeExercises: dataset is a small synthetic exercises dataset consisting of ∼180M tokens of Python exercises and solutions.
Training details
- Datasets concatenated using ⟨∣endoftext∣⟩ token to separate files. Training sequence length is 2048. Next token prediction loss is used.
- fp16 training with AdamW optimizer, linear-warmup-linear-decay learning rate schedule, and attention and residual dropout of 0.1.
- Trained on 8 Nvidia-A100 GPUs using deepspeed.
- Pre-training: effective batch size 1024 (including data parallelism and gradient accumulation), maximum learning rate 1e-3 with warmup over 750 steps, and weight decay 0.1, for a total of 36,000 steps. Checkpoint at 24,000 steps as our phi-1-base – this is equivalent to ∼8 epochs (passes) on our CodeTextbook dataset for a total of little over 50B total training tokens. Trained for 4 days.
- Fine-tuning: effective batch size of 256, maximum learning rate 1e-4 with 50 steps of warmup, and weight decay 0.01. We train for total of 6,000 steps and pick the best checkpoint (saved every 1000 steps). Trained for 7 hours.
Additional Findings
- Phi-1 Limitations:
- phi-1 is specialized in Python coding
- phi-1 lacks the domain-specific knowledge of larger models such as programming with specific APIs or using less common packages
- Due to the structured nature of the datasets and the lack of diversity in terms of language and style, phi-1 is less robust to stylistic variations or errors in the prompt
Future Direction:
- It is unclear what scaling might be necessary to overcome the limitations (both for the model size and the dataset size).
- Significant gains could be achieved by using GPT-4 to generate the synthetic data instead of GPT-3.5. (we noticed that GPT-3.5 data has a high error rate. It is interesting that phi-1 is able to achieve such high coding proficiency despite those errors)
- Developing good methodology for creating high-quality datasets is a central direction of research:
- One challenge is to ensuring dataset covers all the relevant content and concepts, in a balanced and representative way.
- Another challenge is to ensuring dataset is truly diverse and non-repetitive.
- We still lack a good methodology to measure and evaluate the amount of diversity and redundancy in the data.
Textbooks Are All You Need II: phi-1.5 technical report (Sep 2023)
The paper goes on the previous work on phi-1 uses the same architecture but this time focuses on common sense reasoning in natural language.
Architecture
- Similar to phi-1: 24 layers, 32 heads, each head dimension 64.
- Rotary embedding with rotary dimension 32.
- Context length 2048.
- Flash attention for training speed-up
Training data
- phi-1 training data (7B). (6b filtered web data and 1B synthetic data)
- Newly created synthetic textbook-like data (20B).
- 20K topics are selected to seed generation. Samples from web datasets are used for diversity in generation prompts.
Training details
- Random initialization with constant learning rate 2e−4 (no warm up)
- weight decay 0.1.
- Adam optimizer with momentum 0.9, 0.98, and epsilon 1e-7.
- fp16 with DeepSpeed ZeRO Stage 2.
- GPUs: 32xA100-40G
- Training time: 8 days
- Batch size 2048, and train for 150B tokens, with 80% from the newly created synthetic data and 20% from phi-1 training data.
- Personal Note: 0.8 * 20B + 0.2 * 7B = 16B + 1.4B = 17.4B tokens. Which means roughly 9 epochs.
Filtered web data
- To better understand importance web data, 95B tokens of filtered web data generated. (88B from Falcon refined-web, 7B from Stack+)
- phi-1.5-web-only model is trained only on filtered web data (20% code data)
- phi-1.5-web model is trained on filtered web data (40%), phi-1’s code data (20%), newly created synthetic data (%40).
Benchmark results
- Common sense reasoning: phi-1.5-web significantly outperforms all. phi-1.5 (no web data) performs slightly worse.
- Language understanding and knowledge: The difference is not so significant.
- Multi-Step Reasoning: Web data helps a lot. phi-1.5 coding ability is close to phi-1 which was trained purely on code.
Additional Findings
- Creation of a robust and comprehensive dataset requires intricate iterations, strategic topic selection, and a deep understanding of knowledge gaps to ensure quality and diversity of the data.
- We speculate that the creation of synthetic datasets will become, in the near future, an important technical skill and a central topic of research in AI.
Future Direction
- Expanding the synthetic dataset to cover a broader array of topics, and to fine-tune phi-1.5 for more specific tasks.
- Perhaps achieving ChatGPT’s level of capability at the one billion parameters scale is actually achievable?
Phi-2: The surprising power of small language models (Dec 2023)
- Phi-2 (opens in new tab), a 2.7 billion-parameter language model that demonstrates outstanding reasoning and language understanding capabilities,
- Showcasing state-of-the-art performance among base language models with less than 13 billion parameters. On complex benchmarks Phi-2 matches or outperforms models up to 25x larger, thanks to new innovations in model scaling and training data curation.
- Our key insights for breaking the conventional language model scaling laws with Phi-2 are twofold:
- training data quality plays a critical role in model performance.
- innovative techniques to scale up, starting from our 1.3 billion parameter model, Phi-1.5, and embedding its knowledge within the 2.7 billion parameter Phi-2. This scaled knowledge transfer not only accelerates training convergence but shows clear boost in Phi-2 benchmark scores.
Training Details
- Trained on 1.4T tokens from multiple passes on a mixture of Synthetic and Web datasets for NLP and coding.
- Took 14 days on 96 A100 GPUs
- Phi-2 is a base model
- Context length: 2048 tokens
- Dataset size: 250B tokens, combination of NLP synthetic data created by GPT-3.5 and filtered web data from Falcon RefinedWeb and SlimPajama, which was assessed by GPT-4.
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone (Apr 2024)
- phi-3-mini, a 3.8 billion parameter language model trained on 3.3T tokens.
- For comparison; phi-2 was 2.7B parameters trained 1.4T tokens data.
- Training dataset: Scaled-up version of the one used for phi-2, composed of heavily filtered web data and synthetic data.
- Base model trained on 4K context length. LongRope used to extend context length to 128K (phi-3-mini-128K).
- Uses similar tokenizer to Llama 2 with a 32K vocabulary size for compatibility for open source tools.
- phi-3-mini can be quantized to 4-bits so that it only occupies ≈ 1.8GB of memory (12 tokens per second on a iPhone 14 with A16 Bionic chip)
Details
- Trained using bfloat16
- The model uses 3072 hidden dimension, 32 heads and 32 layer
- Removed BoS tokens and add some additional tokens for chat template.
-
Chat template is: < user >/n Question < end >/n < assistant >
Scaling Up
- 7B (phi-3-small) and 14B(phi-3-medium) models trained for 4.8T tokens.
- An additional 10% multilingual data was also used for this model.
- Personal Note: 3.3T + 10% more means, 3.6T tokens. May be it was trained on the same dataset
- Uses the tiktoken tokenizer with 100K vocabulary size and 8K context length for better multilingual support
- 32 layers and a hidden size of 4096
- Group Query Attention: 4 queries sharing 1 key.
- 14B model with similar to architecture and tokenizer with the mini model, with 40 heads, 40 layers embedding dimension 5120.
- Used same data with mini model with more iterations, 4.8T tokens.
Pre-training
- Using high quality training data deviates from the standard scaling-laws.
- raining data of consists of heavily filtered web data (according to the “educational level”) from various open internet sources, as well as synthetic LLM-generated data.
- 2 stage pre-training
- Phase-1 comprises mostly of web sources aimed at teaching the model general knowledge and language understanding.
- Phase-2 merges even more heavily filtered web data (a subset used in Phase-1) with some synthetic data that teach the model logical reasoning and various niche skills.
- Filter the web data to contain the correct level of “knowledge” and keep more web pages that could potentially improve the “reasoning ability” for the model. (Personal note: It is interesting to know how «correct level of “knowledge”» is determined. Following statement is particularly important: As an example, the result of a game in premier league in a particular day might be good training data for frontier models, but we need to remove such information to leave more model capacity for “reasoning” for the mini size models.)
Post Training
SFT leverages highly curated high-quality data across diverse domains, e.g., math, coding, reasoning, conversation, model identity, and safety. The SFT data mix starts with using English-only examples.
DPO data covers chat format data, reasoning, and responsible AI (RAI) efforts. We use DPO to steer the model away from unwanted behavior, by using those outputs as “rejected” responses.
As part of the post-training process, developed a long context version of phi-3-mini with context length limit enlarged to 128K instead of 4K. Long context extension has been done in two stages, including long context mid-training and long-short mixed post-training with both SFT and DPO.
Limitations
- The model simply does not have the capacity to store too much “factual knowledge”
- The model is restricted the language to English.
Future Direction
- Exploring multilingual capabilities for Small Language Models is an important next step, with some initial promising results on phi-3-small by including more multilingual data.
- There remains challenges around factual inaccuracies (or hallucinations), reproduction or amplification of biases, inappropriate content generation, and safety issues.
- The use of carefully curated training data, and targeted post-training, and improvements from red-teaming insights significantly mitigates these issues across all dimensions. However, there is significant work ahead to fully address these challenges.