Effective Long-Context Scaling of Foundation Models Paper Notes
This article includes my notes on “Effective Long-Context Scaling of Foundation Models” paper. All images if not stated oherwise are from the paper.
Intro
- Continually pretraining from LLAMA 2 checkpoints with additional 400 billion tokens formed as long training sequences.
- The smaller 7B/13B variants are trained with 32,768-token sequences.
- 34B/70B variants are trained with 16,384-token sequences.
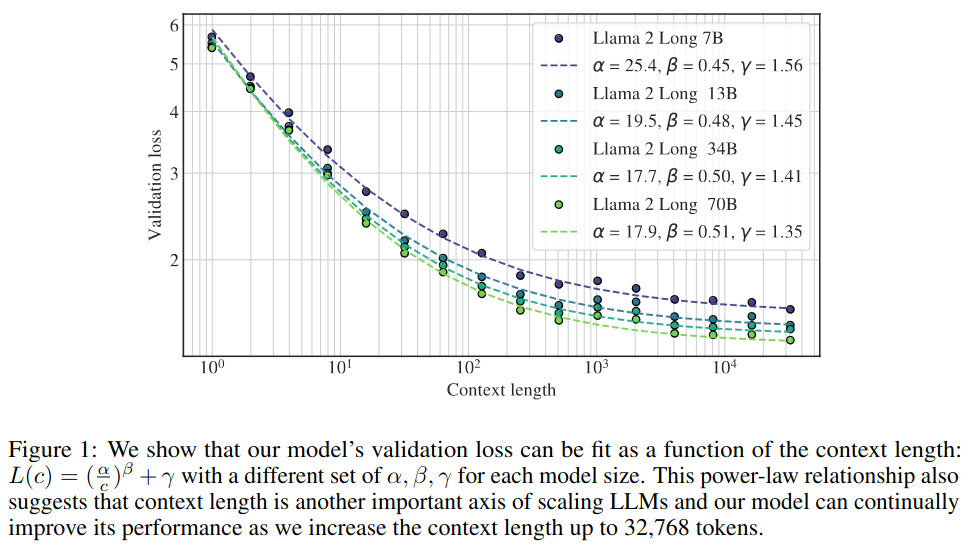
- Shows a clear power-law scaling behavior with respect to context lengths. (Figure 1)
- Observed significant improvements on long-context tasks but also modest improvements on standard short-context tasks, especially on coding, math, and knowledge benchmarks.
- Used a simple and cost-effective procedure to instruction finetune our continually pretrained long models without any human-annotated data.
Method
Continual-Pretraining
- Training with longer sequence lengths can introduce significant computational overhead due to the quadratic attention calculations.
- Similar long-context capabilities can be learned by continually pretraining from a short-context model.
- Original llama-2 architecture slightly modified for positinal encodings to model to attend longer.
- Sparse attention from (Child et al., 2019) not applied; because, given LLAMA 2 70B’s model dimension (h = 8192), the cost of attention matrix calculation and value aggregation only becomes a computation bottleneck when the sequence length exceeds 49,152 (6h) tokens.
Positional Encoding: A minimal yet necessary modification on the RoPE positional encoding for long context modelling (Roformer: Enhanced transformer with rotary position embedding, 2022): decreasing the rotation angle (controlled by the hyperparameter “base frequency b”), which reduces the decaying effect of RoPE for distant tokens.
Data Mix: The quality of the data plays a more critical role than the length of texts for long-context continual pretraining. See section “Pretraining Data Mix” for more details.
Optimization Details:
- The same number of tokens per batch as in LLAMA 2
- All models trained for a total of 400B tokens over 100,000 steps.
- With FLASHATTENTION, there is negligible GPU memory overhead.
- Increasing the sequence length from 4,096 to 16,384 for the 70B model, caused speed loss around 17%.
- a cosine learning rate schedule with 2000 warm-up steps.
- 7B/13B models, learning rate 2e−5
- 34B/70B models, learning rate 1e−5 (marked to be important to set a smaller learning rate for larger models to get monotonically decreasing validation losses)
Instruction Tuning
- Self-intruct method is used to generate long data using Llama 2 chat model.
- Synthetic data is augmented with RLHF data used in Lllama 2 chat.
- Data generation process:
- Select a long document from pretraining corpus
- Selet a random chunk
- Prompt llama 2 chat generate question-answer pairs based on the chunk
- Collect long and short answers with different prompts
- Use self critique to verify model generated answers
- Use the long document and question answer pair as a training instance.
- Short instruction data concatanated to have 16,384-token sequences.
- Long instruction data is not concatanated. Just right padded.
- The interesting part is unlike standard instruction tunning which only calculates loss on the output tokens, this method also calculate the language modeling loss on the long input prompts (gives consistent improvements on downstream task).
Main Results
Pretrained Model Evaluation
Short Tasks:
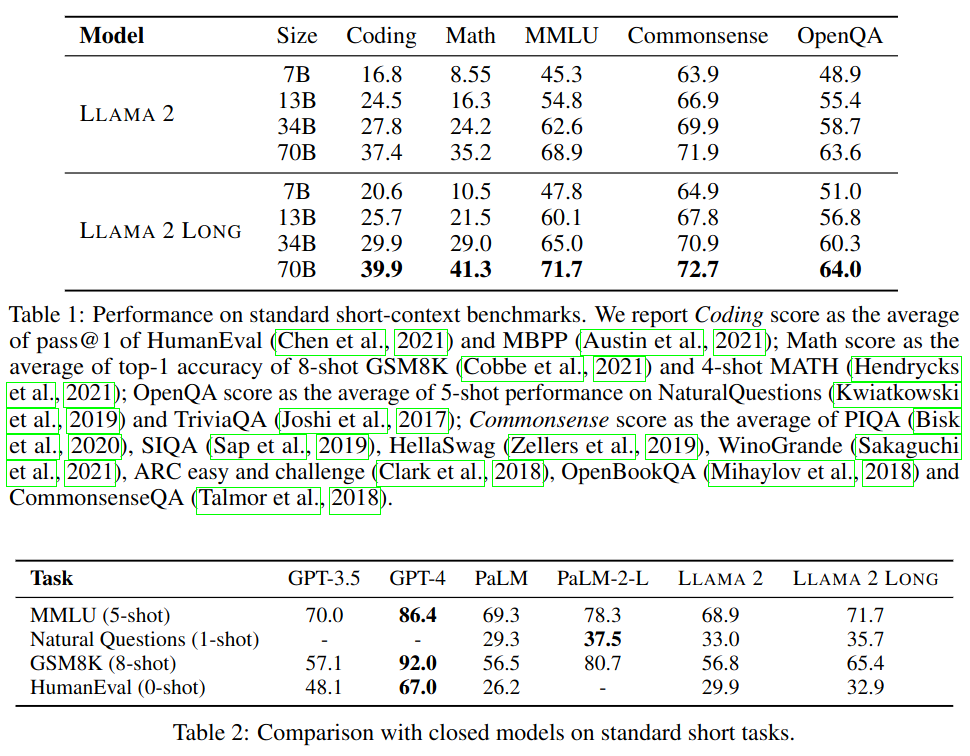
Short task performans shows no degredation. It is either similar or better. Improvements shown in Table 1 and 2 are attributed to additional training steps and the knowledge learned from the new long data.
Long Tasks:
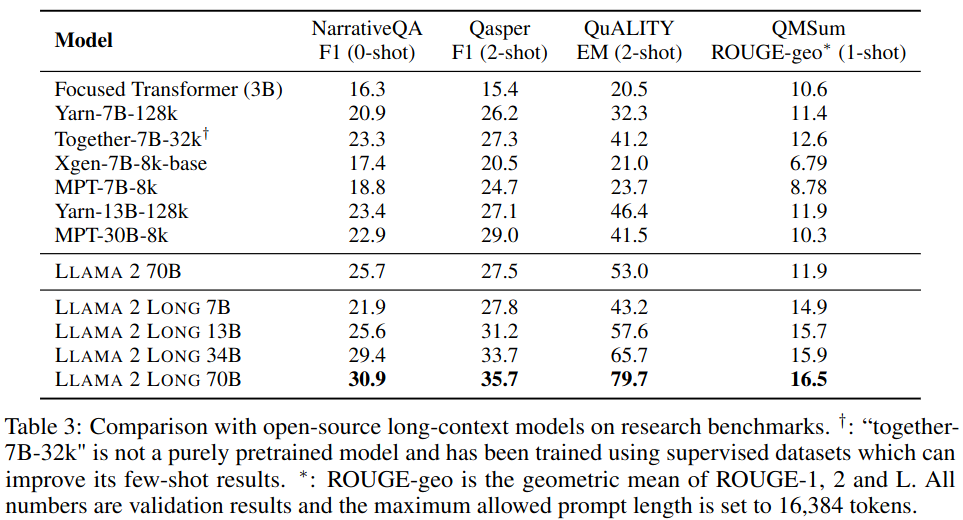
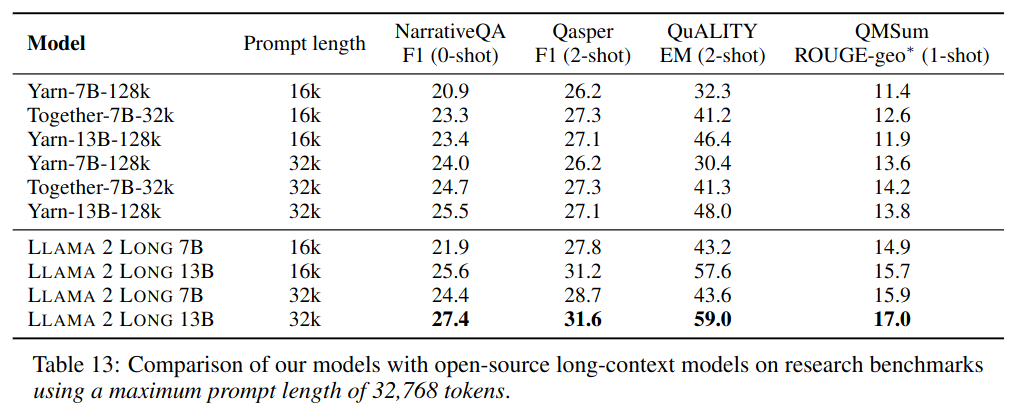
Effective Context Utilization:
Results on each long task improve monotonically as the context length is increased as shown in Figure 2 of the paper.
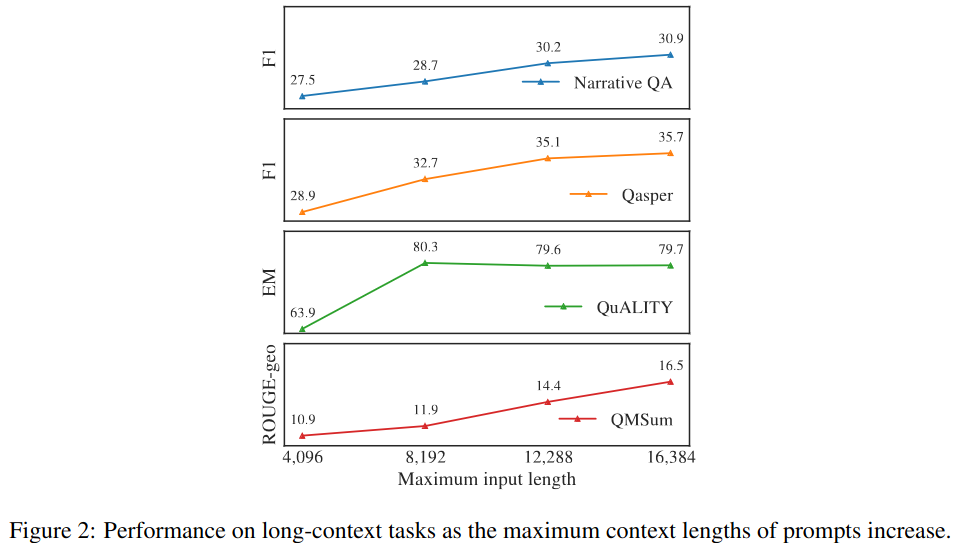
- The model continues to show gain in performance (on the language modeling loss) up to 32,768 tokens of text, despite having diminishing returns.
- Larger models can leverage the contexts more effectively.
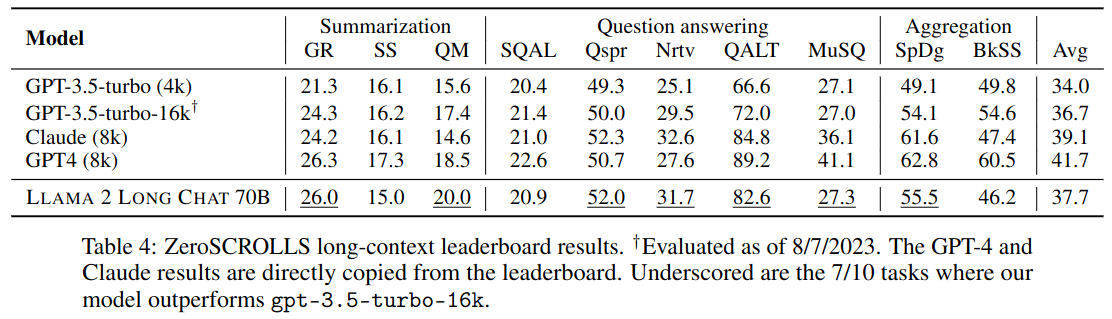
Instruction Tuning Results
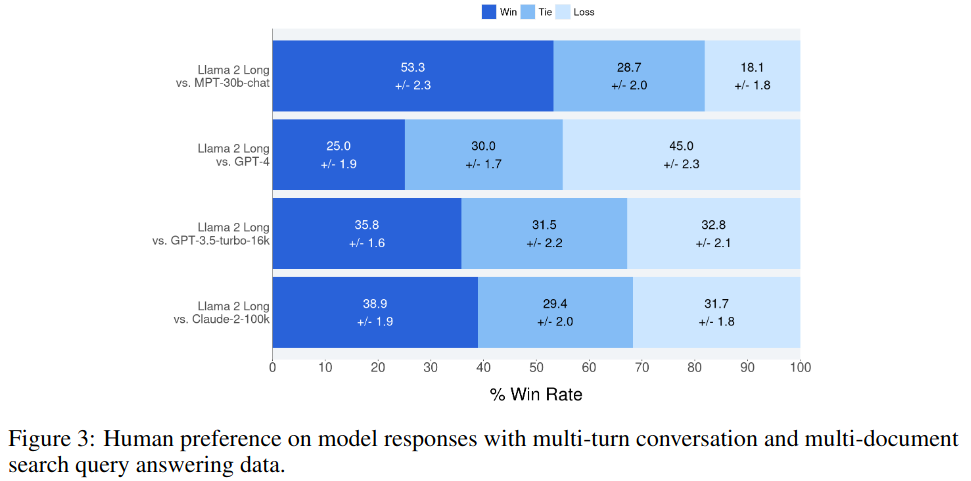
Human Evaluation
Analysis
Positional Encoding for Long Text
Original llama 2 architecture could only attend to up to 4000-6000 tokens, even after extensive long-context continual pretraining. This bottleneck comes from the ROPE positional encoding used in LLAMA 2 series which imposes a heavy decay on the attention scores3 for distant tokens. A simple fix is to do a modification to the default RoPE encoding to reduce the decaying effect – increasing the “base frequency b” of ROPE from 10, 000 to 500, 000, which essentially reduces the rotation angles of each dimension, which is called Rope Adjusted Base Frequency (ABF)
In this section, Rope ABF is compared to alternatives and verified.
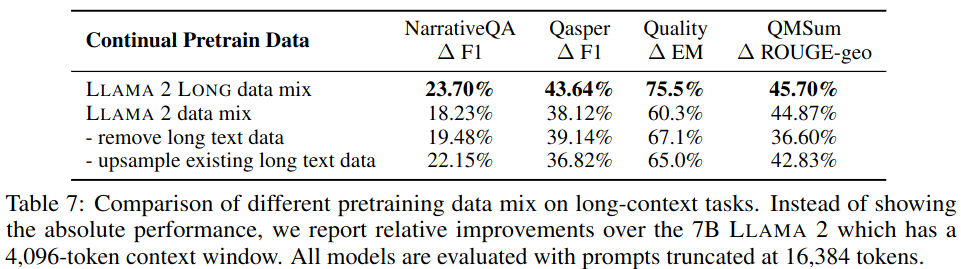
Pretraining Data Mix
This sections suggests that long-context LLMs can be effectively trained even with very limited long data and the improvements of the pretrain data over the one used by LLAMA 2 mostly come from the quality of the data itself, instead of the length distribution difference.
Instruction Tuning
Instruction tuning only calculates loss on the output tokens, however paper adds language modeling loss (loss on the whole sequence). It is suggested adding Language modelling loss over the long context inputs makes learning more stable and gives consistent improvements on downstream tasks when input and output lengths are un-balanced.
