Scaling Instruction-Finetuned Language Models Paper Notes
Paper explores inscruction fine-tuning with focus on:
- Scaling number of tasks
- Scaling model size
- Fine-tuning of Chain of Thougts data
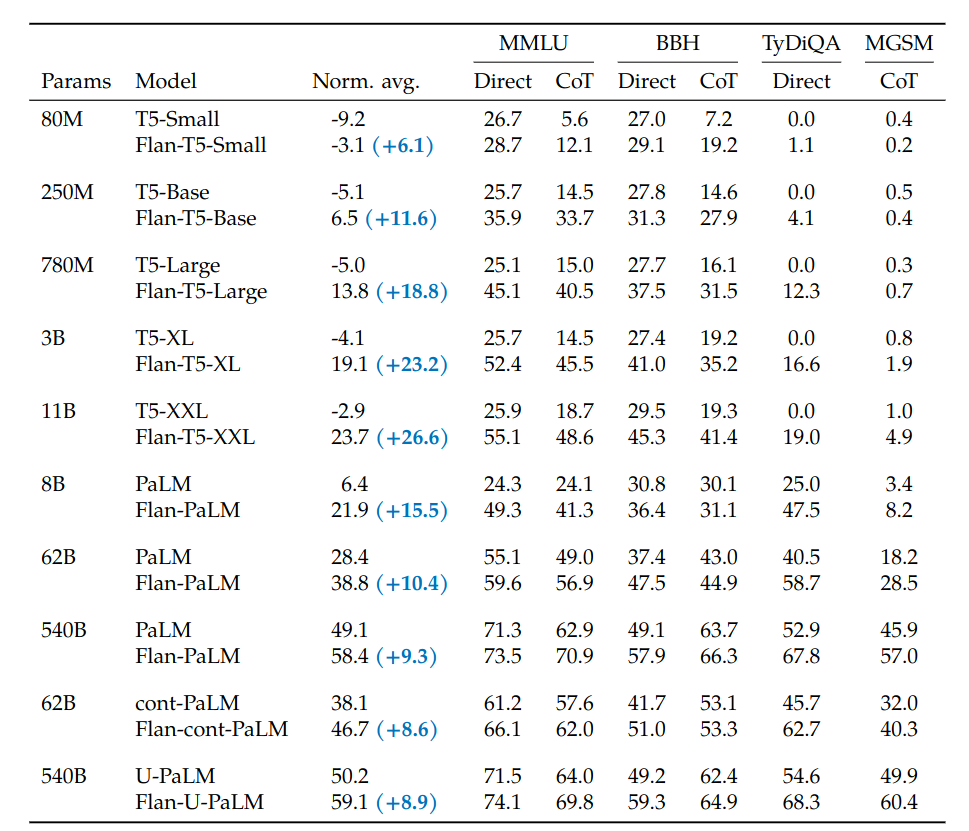
Experiments show that instruction finetuning does scale well with the number of tasks and the size of the model. Adding CoT datasets into the fine-tuning mixture improves reasoning abilities and enables better performance on all evaluations.
Authors trained Flan-PaLM model fine-tuned on 1.8k tasks and CoT data which outperforms PaLM.
Flan Finetuning
Flan stands for finetuning language models. Fintuned models are called with flan prefix.
Finetuning Data
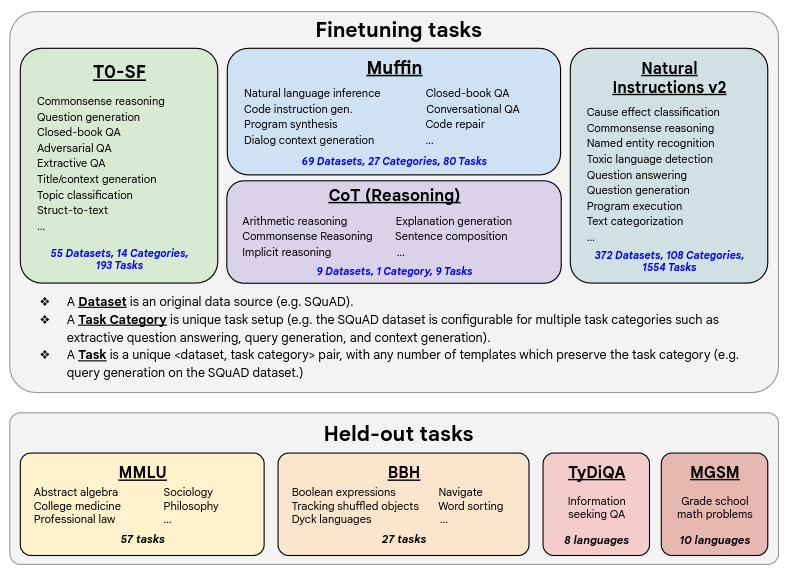
Task mixtures: Used 1,836 finetuning tasks by combining four mixtures from prior work: Muffin (Multi-task finetuning with instructions), T0-SF (sans Flan), NIV2 (Natural Instructions v2), and CoT (Reasoning).
Each dataset contains different number of examples. For a balanced representation for each task, each task is sampled differently.
Finetuning Procedure
Learning rate, batch size and the dropout are stated to be the most important hyperparameters for instruction finetuning.
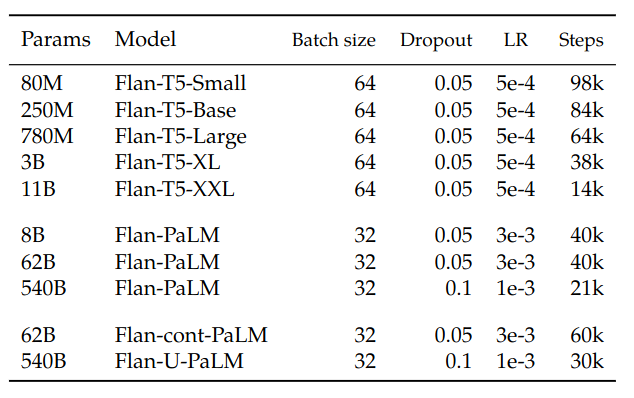
- Constant learning rate schedule
- Adafactor optimizer
- Packing to combine multiple training examples into a single sequence, separating inputs from targets using an end-of-sequence token
- Masking is applied to prevent the tokens from attending to others across the packed example boundary.

Results