New Turkish Pre-training Datasets
Language model pre-training requires massive amount of high quality text. For Turkish language pre-training there are not many options available.
C4-TR Dataset
Multilingual C4 dataset[1] is published in 2021. It has been a major source of Turkish text for language pre-training. However, a quick exploration of the C4 dataset reveals that it contains low-quality documents. There are character encoding issues, obscene language other kind of flaws.
C4-TR-Fineweb Dataset
Huggingface released Fineweb[3,4] dataset, a high quality English only corpus. They also announced they will publish a multilingual dataset. But at the time of training planning, it was not published yet. (At the time of writing this post, fineweb2 was published)
Huggingface Fineweb dataset release was accompanied by a data processing framework, Datatrove[5], which was used to produce the fineweb. It contains filters used to produce the Fineweb dataset. I decided to apply filters to the TR subset of C4 dataset to obtain a higher quality Turkish text dataset.
I called the new dataset C4-TR-Fineweb[7]. In addition to fineweb filters, I created special filters to remove additional flaws and called the new dataset C4-TR-Fineweb-Plus[8]. I used C4-TR-Fineweb-Plus to train a 40M parameter transformer.
Fineweb2-TR Dataset
By the time I completed training of the transfomer on C4-TR-Fineweb-Plus dataset, huggingface released Fineweb2[12], which was promised earlier during the release of Fineweb. Fineweb2 came with a substantial amount of Turkish text. Initial exploration on TR subset reveals it had problems similar to original TR subset of C4 dataset.
Then I decided to tran 2 more models using C4-TR and Fineweb2-TR datasets.
Training Details
I used first 10B tokens from each dataset to train models. Context length was 1024. Batch size was roughly 0.5M. For validation, first 10m tokens from the validation split of the datasets was used. Training loss depicted in the chart is obtained using the first 10M tokens from the training dataset.
Results
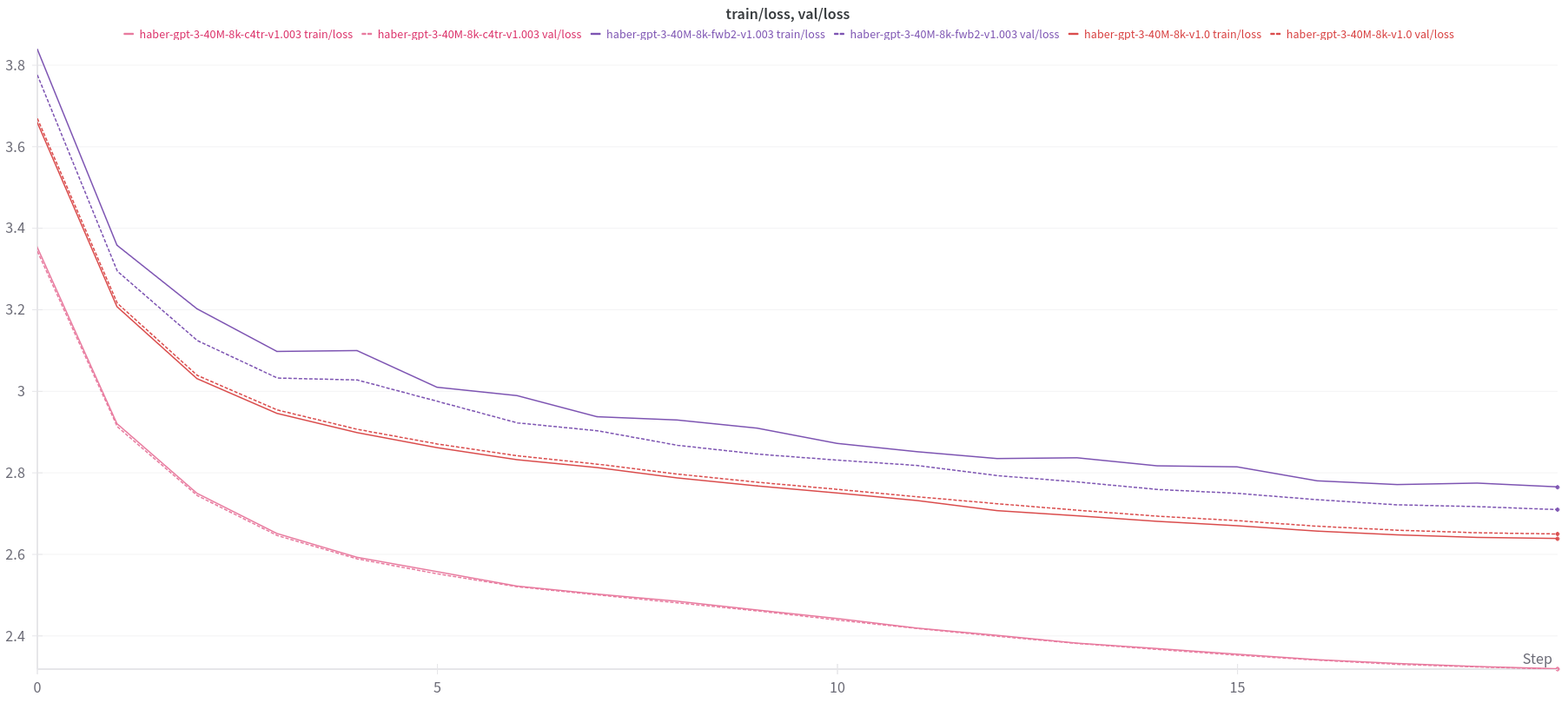
Surprisingly, model trained on C4-TR yielded the best training loss curve. It is also worth pointing out that training and validation loss curves are very tightly coupled for C4-TR dataset. I could not answer cause of this phenomenon.
Loss curves for the model trained on C4-TR-Fineweb, showed significantly worse curves.
The model trained on Fineweb2-TR model yielded the worst training loss curves. Over the course of the training, training and validation losses varied significantly in contrast to the other models.
News-TR-1.8M Dataset For Validation
As an additional metric for validation performance, a secondary dataset, news-tr-1.8M[13], was used. The same subset of the news-tr-1.8M dataset was used for validation on all models.
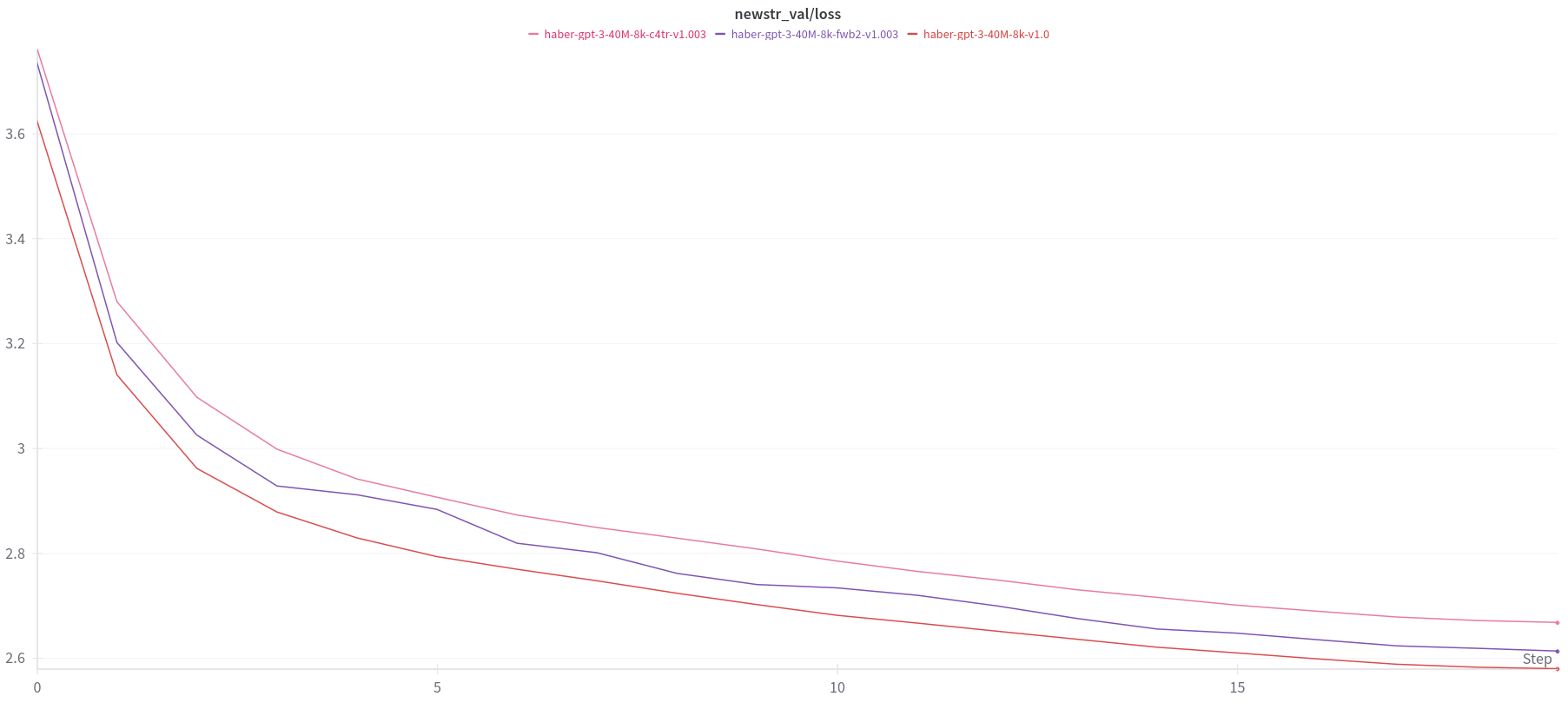
Validation loss on news-tr dataset, showed a different picture. The model trained on c4-tr-fineweb dataset showed best loss curve. Despite being superset of c4-tr-fineweb, the model trained on c4-tr dataset yields worst loss curve. Fineweb2-TR on the other hand results in a loss curve that is in between.
So far, loss curves depicted a confusing picture. What we need is a third metric to end the confusion.
Tarif Datasets
I decided to compare model performance on a dataset similar to HellaSwag. HellaSwag has a Turkish translated version which I do not trust because I think it fails to capture linguistic differences and deliberate errors in the original dataset.
Inspired by HellaSwag, I decided to create a new dataset. Given a context, the model should be able to select next action accurately among closely related options. The easiest way to create such a dataset was to turn to cooking recipes domain.
I created tarif_parts_21k[16] dataset and its variants. The tarif_parts_21k dataset is not useful on its own.
tarif_ilk_adim_20k[14] dataset contains 20k samples. Each sample has a context and a list of possible continuations and a label pointing to the correct continuation. The context includes a title for the recipe and ingredients. The label shows the first instruction step that should be selected among possible continuations list.
tarif_ikinci_adim_18k[15] dataset contains 18k samples. It is similar to tarif_ilk_adim_20k dataset with slight differences. Context of tarif_ikinci_adim_18k rows contain first instruction step. The task is to select the second instruction.
This benchmarks expects the model to consider the recipe title and the given ingredients and predict the continuations accurately. Each sample has a single correct continuation. Two of the continuations comes from the same recipe which should be challenging for the model to differentiate. One of the continuations come from a random recipe in the dataset which should be easier to detect because it will potentially mention ingredients that is not part of the ingredient list of the current recipe.
Tarif Benchmark Results
First 1000 samples are selected from the benchmark datasets. For each possible continuation, model generates logits and an average loss is calculated. The continuation with smallest lost is used as the model guess. The guess is compared to the label. Since there are 4 options, random guessing score is 0.25. All models hit higher scores which suggests that they have a some sort of understanding of the problem.
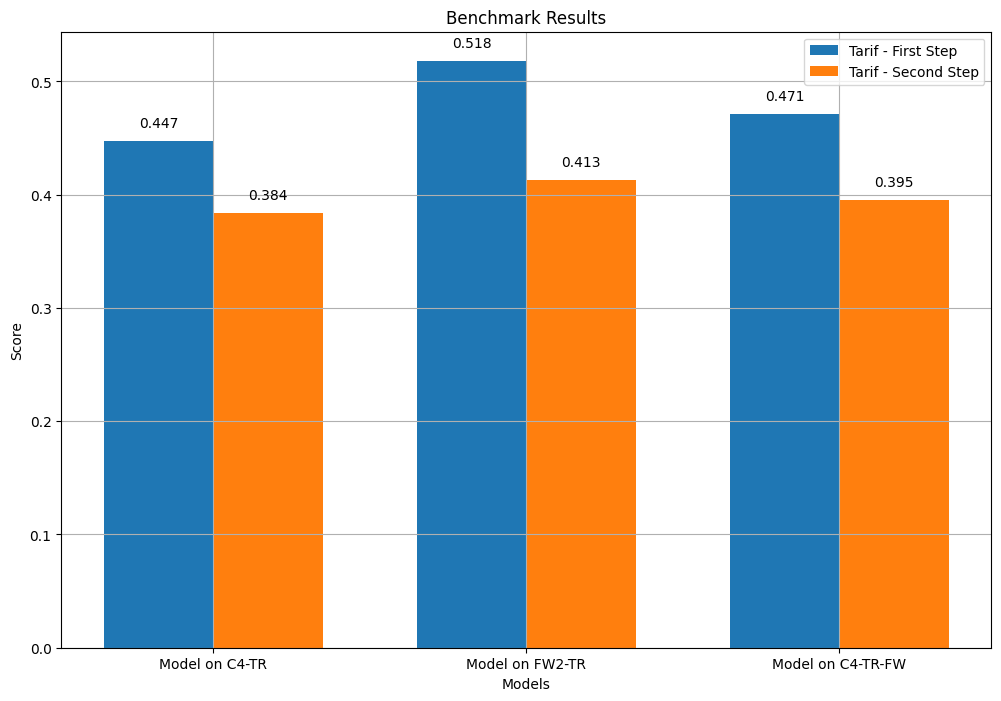
Surprisingly, the model trained on Fineweb2-TR dataset scores significantly better than the other models. C4-TR-Fineweb score is the second best. The model trained on C4-TR scores slightly worse than the C4-TR-Fineweb model.
All models do a better job at guessing the first step. This is probably partly due to the fact that first instructions include artifacts that make them obvious choices (e.g. İlk önce (first of all)).
Conclusion
The results are insufficient to declare a dataset as the winner. While Fineweb2-TR dataset gives a model that is better at predicting next step in a recipe, C4-TR-FW dataset gives a model that is better at news-tr dataset.
A possible follow-up to this study is to train larger models (e.g. 100M) and use more benchmarks.
References
1- mT5: A massively multilingual pre-trained text-to-text transformer
3- Fineweb
4- FineWeb: decanting the web for the finest text data at scale
5- Datatrove
9- HaberGPT3 on C4-TR-Fineweb-Plus
12- Fineweb2 Dataset
14- tarif_ilk_adim_20k Dataset