Haber GPT-2
HaberGPT2 is a decoder only language model with 100M parameters. It is trained from scratch using turkish news. This post shares details about training process.
Data
The model is trained using habanoz/news-tr-1.8M dataset[1]. See [2] on how dataset is generated.
Tokenizer
The Tokenizer was trained on the habanoz/news-tr-1.8M dataset using the “sentencepiece” library[3].
A relatively small vocabulary size of 8192 was chosen to prioritize faster training speeds, resulting in a 33% increase in throughput compared to a 32K vocabulary size. This smaller vocabulary enables the use of larger micro batch sizes, making the model training more efficient. However, the impact of vocabulary size on the performance of downstream tasks was not investigated.
| Vocab Size | Tokens | Relative |
|---|---|---|
| 32K | 871.296.394 | 81% |
| 16K | 955.567.472 | 89% |
| 8K | 1.072.343.909 | 100% |
Table shows number of tokens for habanoz/news-tr-1.8M dataset using each tokenizers. Relative column is relative to 8K tokenizer. With 8k vocabulary, habanoz/news-tr-1.8M dataset contains 1B tokens.
Architecture
I have trained many 10M and 40M parameter models to find optimum architecture for throughput. Starting from the original GPT2 architecture, I have decided to include following changes:
-
Rotary Positional Embedding (RoPE): RoPE[4] harms throughput while improving validation loss. To mitigate throughput degradation, I have pre-computed and cached rotation matrices. With RoPE, throughput is down by 10% while validation loss improves by 2%. Despite significant impact on throughput, I have decided to continue with RoPE.
-
Group Query Attention (GQA): GQA improves throughput with no visible impact on validation loss. Throughput gain is about 2%. For two value heads, one key and one query head is used.
-
Deep Layers: Deep models are known to outperform wide models[5]. Deeper models are better at finding complex relationships between tokens while wider models have more capacity to learn facts. For smaller models depth is more preferable.
-
Embedding Sharing: Token embedding weights and output layer weights are shared. While embedding sharing has a small performance impact, it is a common practice for small models[5,9]. For large models, output layer size is negligible hence output layer is not shared with token embedding layer.
During my testing, I explored various activation and normalization techniques to optimize throughput.
Notably, I avoided using SwiGLU[7] activation, as employed in [5], due to significant throughput degradation observed in my experiments.
I also experimented with Squared ReLU[8] activation, but initially found it to negatively impact throughput. I decided not to use Squared ReLU. However, later experiments using torch.compile revealed that it actually improves throughput, contrary to my initial findings.
Regarding normalization, I found RMSNorm[6] to hurt throughput, which was unexpected given its simplicity compared to LayerNorm. I suspect that this may be due to the GPU I used, which may lack optimized kernels for RMSNorm. Unfortunately, using torch.compile did not alleviate this issue with RMSNorm.
Architecture Details:
-
Number of Hidden Layers: 32
-
Model dimension : 512
-
Number of Heads: 8 (4 kq heads, 8 value heads)
-
Sequence Length: 512
-
Vocabulary Size: 8192
-
Total Parameters: 108.04M
-
Total Parameters w/o Embeddings: 108.03M
Training
The model is trained using 11B tokens (11 epochs). Each sample is prefixed with BOS token and suffixed with EOS token. Samples are concatenated to fit sequence length.
-
Optimizer: AdamW (beta1 0.9, beta2 0.95)
-
Learning Rate: 0.0018
-
Learning Rate Scheduler: Cosine schedular (2000 warmup steps then decay to 10% of initial LR)
-
Batch size: 552960 (0.5M)
-
Number of Steps: 20K
The training process utilized 2 Tesla T4 GPUs in mixed precision mode, which completed in approximately 102 hours, equivalent to roughly 4 days.
Sequence length limitation
Sequence length is only 512, which is not typical in LLM training after original GPT1 model. Attention calculation has quadratic complexity. The popular solution is to use Flash attention which is only available for more recent GPUs starting from volta series. Since tesla series of GPUs are NOT supported by flash attention, I cannot increase sequence length, without having access to more recent GPUs.
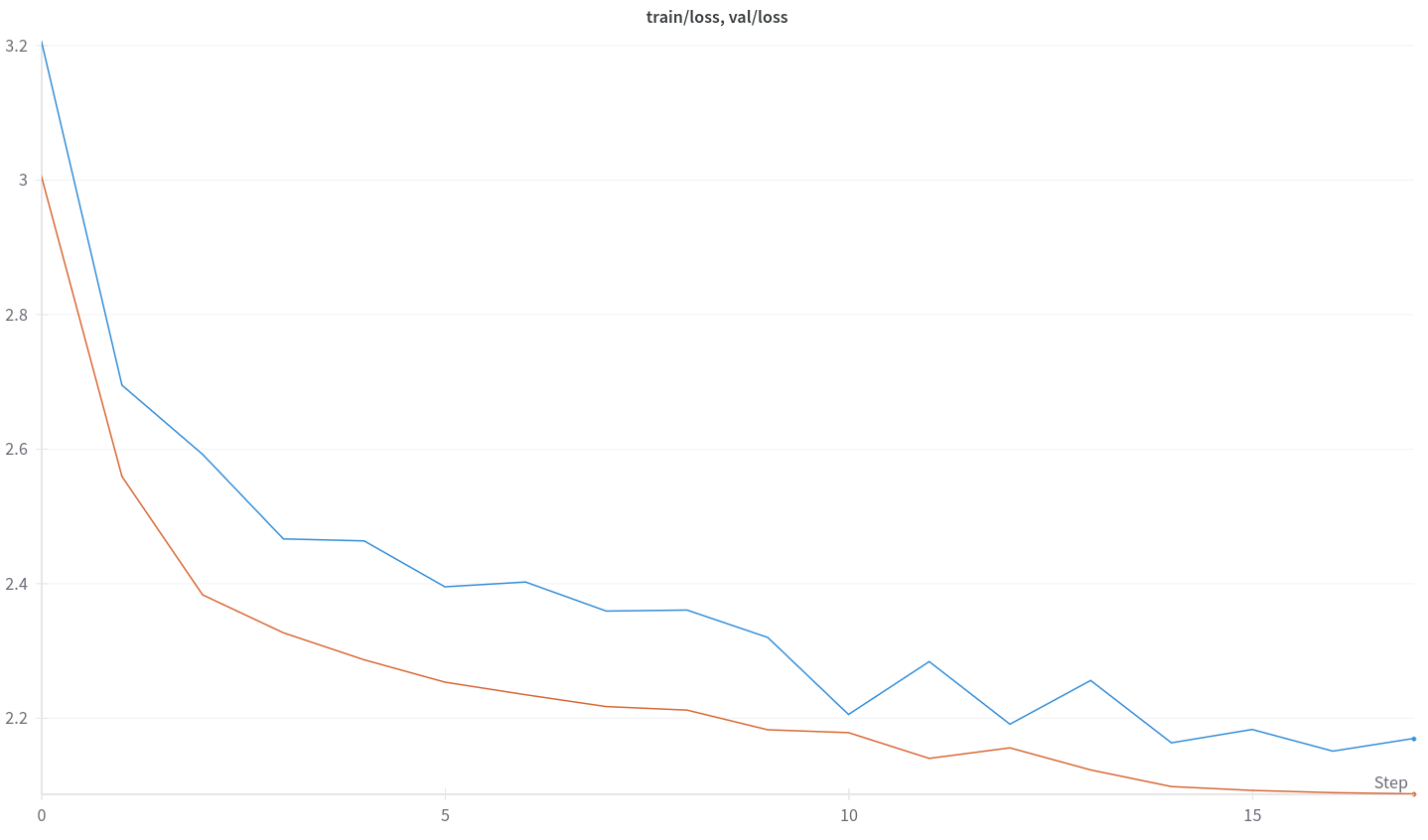
Results
Final validation loss is 2.09, perplexity is 8.06. A test notebook is provided to test the model [11].
The model can output coherent completions in wide variety of topics included in the training set. However, the model does not produce and newlines. Sometimes outputs are not logical continuations. Sometimes, especially in greedy decoding, model tends to repeat sentences.
My conclusions:
-
News are not an ideal source to learn the language. There are unnecessary repetitions and long sentences.
-
Sequence length limitation maybe a major obstacle for model output quality.
-
Training for 11 epochs is too much. It is shown that multi-epoch training causes degradation[10]. A larger dataset is needed to avoid reusing tokens.
I share model weights [12], dataset[1], training code[13] and testing notebook[11] for practitioners.
References
2- Building news-tr-1.8M Dataset
4- ROFORMER: ENHANCED TRANSFORMER WITH ROTARY POSITION EMBEDDING
5- MobileLLM: Optimizing Sub-billion Parameter Language Models for On-Device Use Cases
6- RMSNorm
7- GLU Variants Improve Transformer
8- Primer: Searching for Efficient Transformers for Language Modeling
9- Language Models are Unsupervised Multitask Learners
10-To Repeat or Not To Repeat:Insights from Scaling LLM under Token-Crisis